Creating Testing Set
One of the most challenging part of this project is to create the testing set, as no tweets come with label we have to label all the tweets by ourself. However, manually labeling tweets is painful and time-consuming. It took our team three hours to label all the tweets of entity "birdman", 1063 tweets. The entity "community" contains even more, 13k tweets, and thus impossible to manually label. Therefore, we decide to construct an active learning system to let the computer label tweets for us.
Active Learning
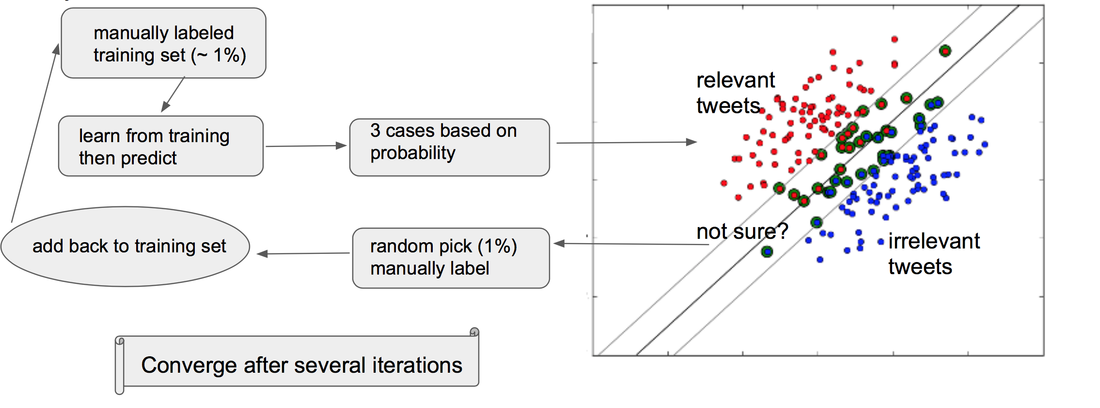
The advantage of the active learning approach is that, instead of labeling every tweets, this approach allowed as to label portion of the total dataset and still generated reasonable accuracy. If higher accuracy is needed, just keep running the algorithm and manually labeling more tweets.
Convergence and Accuracy
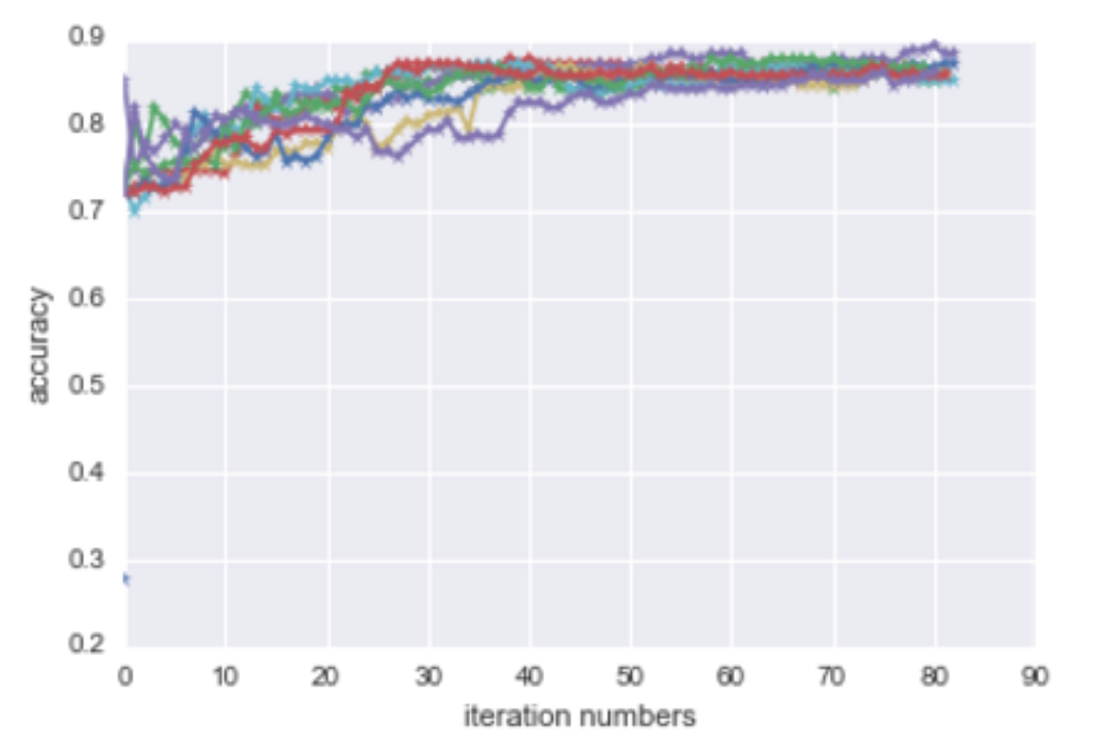
The plot above represent ten different runs of this algorithm on entity "birdman" and its accuracy. In each run, we randomly put aside 200 tweets as testing. Each color represent one single run. As we could see, that although the accuracy of each run varies a lot at the beginning, then all converged and reached a reasonable level of accuracy, ~90%, after 50 iteration.
Since we have manually labeled all the tweets associated with entity "birdman", we are able to compute the accuracy of this active learning algorithm against ground truth. For other test cases we conducted in the project, we use the label generated by this method after 45 iterations as the true label for testing purpose.
Since we have manually labeled all the tweets associated with entity "birdman", we are able to compute the accuracy of this active learning algorithm against ground truth. For other test cases we conducted in the project, we use the label generated by this method after 45 iterations as the true label for testing purpose.
